Databricks — SQL Warehouses

Today, I would like to do a short intro about Databricks SQL Warehouses (formerly SQL endpoint). What is it? Simply, a place where you can work with hive tables through SQL. I can highlight three main functionalities: work with data through SQL, create dashboards/visualizations and alerts based on your data.
When you go to SQL, you see new positions. An SQL editor — a place where you can create queries, Queries — saved queries, Dashboards and Alerts.

Let’s go to the SQL Editor.

I’ve created an exemplary SQL query [iowa_sales] which is a foundation for creating alerts, visualizations and dashboards.
A cool feature is a fact that for this one query, besides a standard table result you can create separate visualizations which can be reused as dashboard components. Like below.

Next cooler feature, you can add filters to your results. They are reusable as well; we will use them in the dashboard.

The next section: Queries, here you can look over saved queries.

In the Dashboards section we can put previously created visuals or add new ones based on the same or another query.
Query selection.

Visualizations built on the top of the selected query.

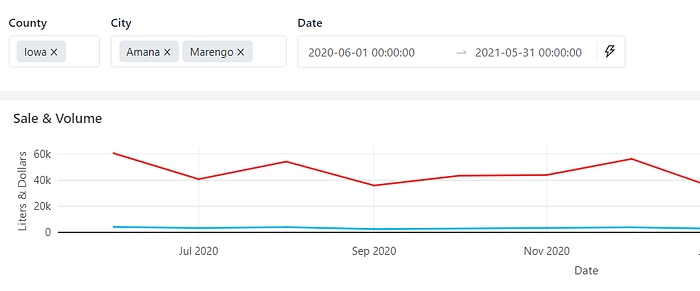
A dashboard example.

Here we can select previously created filters.
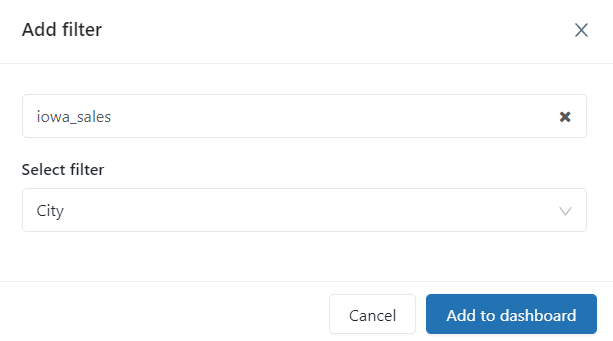
And here are all the filters derived from query visualizations.
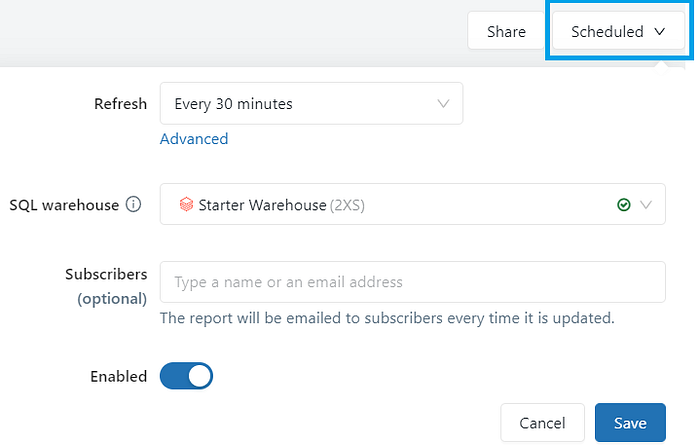
To keep dashboard data updated. You can set a dashboard refresh schedule.
Last point is an Alerts section. Alert sends an email when a defined particular condition is meet — the alert is based on a query created at the beginning.
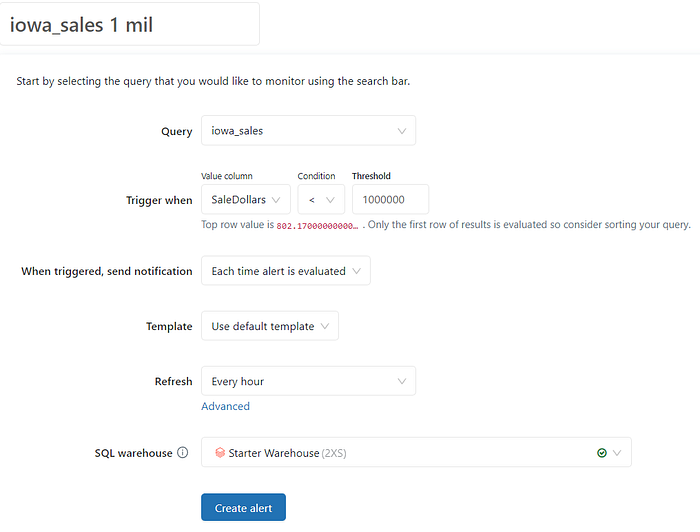
In this case a threshold is 1 000 000 million dollars for a [SalesDollars] aggregated record column.
